Como funciona a inteligência artificial5 exemplos de inteligência artificial no dia a dia
Na web, onde otimização de imagens é tão importante que é incentivada pelo Google, essa descoberta pode ser útil a lojas online, a redes sociais e a sites como o Tecnoblog.
Explicando esse tal de Stable Diffusion
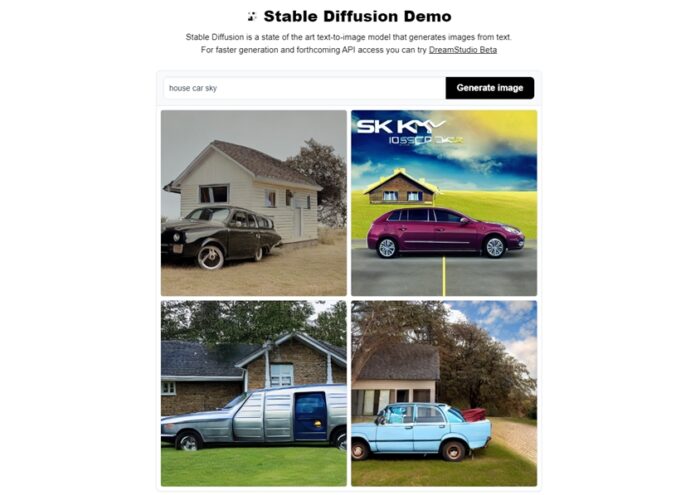
Digamos que o Stable Diffusion é um brinquedo da moda. A exemplo do Dall-E, o mecanismo consegue gerar imagens por meio de instruções dadas via texto, em questão de minutos. Muitos delas são impressionantes. Você pode tirar a prova por conta própria. O Stable Diffusion está disponível em sites como o Hugging Face. Neste último, digitei as seguintes palavras no campo de texto: house (casa), car (carro) e sky (céu). O resultado foi este:
Legal, mas e a compressão de imagens?
Se por um lado ferramentas como o Stable Diffusion vêm incomodando artistas por inundarem comunidades com imagens geradas artificialmente, por outro, atraem a atenção de muitos entusiastas de inteligência artificial. É o caso do engenheiro de software Matthias Bühlmann. Ao testar o Stable Diffusion, ele descobriu que a ferramenta aciona três redes neurais artificiais. Uma delas é a Variational Auto Encoder (VAE), que codifica e decodifica uma imagem dentro de um espaço latente. Entenda espaço latente com uma representação intermediária do resultado esperado. Fazendo uma comparação grosseira, é como se esse espaço representasse um rascunho ou uma versão reduzida da imagem. De fato, o espaço latente contém uma representação com resolução menor da imagem original, mas com detalhes mais precisos. Com isso, a imagem pode ser expandida novamente, sem ficar descaracterizada. O espaço latente é usado para que outro algoritmo de rede neural, o U-Net, entre em ação. Um ruído aleatório é inserido no espaço para esse mecanismo gerar previsões sobre o que ele “vê” ali. É como se o algoritmo fosse uma pessoa tentando identificar formas em nuvens. Esse processo serve para que o ruído seja eliminado de maneira condizente com o resultado esperado e trabalha em consonância com a terceira rede neural, o codificador de texto. Este funciona como um orientador sobre o que o U-Net deve tentar “ver”. Trata-se de uma explicação bastante simplificada. O que importa é saber que tudo isso é combinado para que a imagem solicitada pelo usuário seja gerada. Durante esse processo, a imagem tem “impurezas” removidas. Isso ocorre não necessariamente para deixá-la menor, mas para tornar o resultado mais preciso.
Agora sim, a compressão
Durante o seu experimento, Bühlmann descobriu que os algoritmos do Stable Diffusion podem ser adaptados para apenas fazer compressão de imagem. Para tanto, ele removeu o codificador de texto, mas manteve os procedimentos relacionados ao tratamento da imagem. Nos testes, ele descobriu que os resultados são bastante convincentes. A foto de uma lhama ficou com 6,74 KB de tamanho usando uma ferramenta que compacta a imagem em WebP. Em JPEG, a imagem ficou com 5,66 KB. No Stable Diffusion, a imagem ficou com 4,97 KB e, mesmo assim, apresenta mais detalhes que as anteriores. O resultado não é perfeito, que fique claro. Bühlmann percebeu que rostos ou textos nas imagens podem ficar menos visíveis. Mas é de se presumir que o mecanismo pode ser adaptado e treinado para superar essas limitações. Para quem quiser experimentar ou até colaborar com o projeto, Bühlmann publicou o código-fonte do seu trabalho no Google Colab. Com informações: Ars Technica.